
Note: Before the launch of the Open Philanthropy Project Blog, this post appeared on the GiveWell Blog. Uses of “we” and “our” in the below post may refer to the Open Philanthropy Project or to GiveWell as an organization. Additional comments may be available at the original post.
Note: this post aims to help a particular subset of our audience understand the assumptions behind our work on global catastrophic risks.
One focus area for the Open Philanthropy Project is reducing global catastrophic risks (such as from pandemics, potential risks from advanced artificial intelligence, geoengineering, and geomagnetic storms). A major reason that the Open Philanthropy Project is interested in global catastrophic risks is that a sufficiently severe catastrophe may risk changing the long-term trajectory of civilization in an unfavorable direction (potentially including human extinction if a catastrophe is particularly severe and our response is inadequate).
One possible perspective on such risks—which I associate with the Future of Humanity Institute, the Machine Intelligence Research Institute, and some people in the effective altruism community who are interested in the very long-term future—is that (a) the moral value of the very long-term future overwhelms other moral considerations; (b) given any catastrophe short of an outright extinction event, humanity would eventually recover, leaving humanity’s eventual long-term prospects relatively unchanged. On this view, seeking to prevent potential outright extinction events has overwhelmingly greater significance for humanity’s ultimate future than seeking to prevent less severe global catastrophes.
In contrast, the Open Philanthropy Project’s work on global catastrophic risks focuses on both potential outright extinction events and global catastrophes that, while not threatening direct extinction, could have deaths amounting to a significant fraction of the world’s population or cause global disruptions far outside the range of historical experience. This post explains why I believe this approach is appropriate even when accepting (a) from the previous paragraph, i.e., when assigning overwhelming moral importance to the question of whether civilization eventually realizes a substantial fraction of its long-run potential. While it focuses on my own views, these views are broadly shared by several others who focus on global catastrophic risk reduction at the Open Philanthropy Project, and have informed the approach we’re taking.
In brief:
- Civilization’s progress over the last few centuries—in scientific, technological, and social domains—has no historical parallel.
- With the possible exception of advanced artificial intelligence, for every potential global catastrophic risk I am aware of, I believe that the probability of an outright extinction event is much smaller than the probability of other global catastrophes. My understanding is that most people who favor focusing work almost entirely on outright extinction events would agree with this.
- If a global catastrophe occurs, I believe there is some (highly uncertain) probability that civilization would not fully recover (though I would also guess that recovery is significantly more likely than not). This seems possible to me for the general and non-specific reason that the mechanisms of civilizational progress are not understood and there is essentially no historical precedent for events severe enough to kill a substantial fraction of the world’s population. I also think that there are more specific reasons to believe that an extreme catastrophe could degrade the culture and institutions necessary for scientific and social progress, and/or upset a relatively favorable geopolitical situation. This could result in increased and extended exposure to other global catastrophic risks, an advanced civilization with a flawed realization of human values, failure to realize other “global upside possibilities,” and/or other issues.
- Consequently, for almost every potential global catastrophic risk I am aware of, I believe that total risk (in terms of failing to reach a substantial fraction of humanity’s long-run potential) from events that could kill a substantial fraction of the world’s population is at least in the same ballpark as the total risk to the future of humanity from potential outright extinction events.
Therefore, when it comes to risks such as pandemics, nuclear weapons, geoengineering, or geomagnetic storms, there is no clear case for focusing on preventing potential outright extinction events to the exclusion of preventing other global catastrophic risks. This argument seems most debatable in the case of potential risks from advanced artificial intelligence, and we plan to discuss that further in the future.
Basic framework and terms
Consider two possible heuristics that could be used when evaluating efforts to reduce global catastrophic risk in a utilitarian-type moral framework:
- Minimize expected deaths: Seek a strategy for mitigating and/or adapting to risks of catastrophic events that minimizes expected deaths.
- Maximize long-term potential: Seek a strategy for mitigating and/or adapting to the risks of catastrophic events that minimizes negative consequences from changes to humanity’s long-term trajectory. Changes to be avoided might include existential catastrophes or other negative trajectory changes. This kind of heuristic is associated with people in the effective altruism movement who focus on the long-term future, and has been argued for by Nick Bostrom. (I also defended this view in my dissertation.)
Throughout this post, I focus on the latter.
I discuss two different schools of thought on what the “maximize long-term potential” heuristic implies about the proper strategy for reducing global catastrophic risk. To characterize these two schools of thought, first consider two levels of risk for a catastrophe:
- Level 1 event: A continuous chain of events involving the deaths of hundreds of millions of people, such as an extreme pandemic.
- Level 2 event: A continuous chain of events involving the extinction of humanity, such as a pandemic engineered to kill 100% of the world’s population.
Some events do not sort neatly between the two categories, but that will not be important for the purposes of this discussion.
In making this distinction, I have avoided using the terms “global catastrophic risk” and “existential risk” because they are sometimes used in different ways, and what counts as a “global catastrophic risk” or an “existential risk” depends on long-term consequences of events that are very hard to predict. For example, the Open Philanthropy Project defines “global catastrophic risks” as “risks that could be bad enough to change the very long-term trajectory of humanity in a less favorable direction (e.g. ranging from a dramatic slowdown in the improvement of global standards of living to the end of industrial civilization or human extinction),” some other people who professionally work on existential risk often use the term “global catastrophic risk” to refer to events that kill a substantial fraction of the world’s population but do not result in extinction, reserving the term “existential risk” for events that would directly result in extinction (or have other, more obvious long-term consequences). But the more formal definition of “existential risk” is a risk that “threatens the premature extinction of Earth-originating intelligent life or the permanent and drastic destruction of its potential for desirable future development.” That definition is neutral on the question of whether level 1 events are existential risks. A major purpose of this post is to explore the possibility that level 1 events are existential risks.
Now consider the two schools of thought:
- Level 2 focus: In order to maximize long-term potential, a catastrophic risk reduction strategy should be almost exclusively focused on preventing/preparing for level 2 events.
- Dual focus: In order to maximize long-term potential, a catastrophic risk reduction strategy should seek to prevent/prepare for both level 1 and level 2 events. The threat to humanity’s future potential from level 1 events is not small in comparison with the threat from level 2 events.
I generally associate the first perspective with FHI, MIRI, and many people in the effective altruism community who are focused on the very long-term. For example, Luke Muehlhauser, former Executive Director of MIRI (and now a GiveWell Research Analyst), has argued:
One reason AI may be the most urgent existential risk is that it’s more likely for AI (compared to other sources of catastrophic risk) to be a full-blown existential catastrophe (as opposed to a merely billions dead catastrophe). Humans are smart and adaptable; we are already set up for a species-preserving number of humans to survive (e.g. in underground bunkers with stockpiled food, water, and medicine) major catastrophes from nuclear war, superviruses, supervolcano eruption, and many cases of asteroid impact or nanotechnological ecophagy.
Machine superintelligences, however, could intelligently seek out and neutralize humans which they (correctly) recognize as threats to the maximal realization of their goals.
In contrast, this post argues for the “dual focus” approach. (While we are arguing that preventing level 1 events is important for maximizing civilization’s long-term potential, we are not arguing for the further claim that only level 1 and level 2 events are important for this purpose. See our related discussion of “flow-through effects.”)
There are other possible justifications for a “dual focus” approach. For example:
- Because level 1 events are generally seen as substantially more likely than level 2 events, it may be much easier to get broad support for efforts to reduce risks from level 1 events.
- It might be argued that level 1 events are easier to think about and develop appropriate societal responses for.
- Uncertainty about whether the “maximize long-term potential” heuristic is correct might speak in favor of a dual focus approach.
However, this post focuses on the implications of level 1 events for long-term potential independently of these considerations.
The core of the argument is that there is some (highly uncertain) probability that civilization would not fully recover from a level 1 event, and—with the possible exception of AI—that the probability of level 1 events is much greater than the probability of level 2 events. I would guess that when we multiply these probabilities through, the total risk to humanity from level 1 events is in the same rough ballpark as the total risk from level 2 events (again, bracketing risks from AI). If I and others at the Open Philanthropy Project changed our view on this, we might substantially change the way we’re approaching global catastrophic risks.
Global catastrophes seem much more likely than extinction events
For almost every class of risk I am aware of, less extreme catastrophes seem far more likely than direct extinction events. This claim is consistent with the Google sheet that we published as part of a March update summarizing our conclusions from investigating multiple possible global catastrophic risks. To consider some examples:
- A pandemic—whether natural or engineered—seems much more likely to be a level 1 event than a level 2 event.
- Nuclear conflict causing extreme disruption to global civilization (a level 1 event) seems much more likely than extinction in nuclear winter following a total nuclear exchange between the U.S. and Russia (a level 2 event).
- Most debatably, purposeful misuse of advanced artificial intelligence (a level 1 event or perhaps a negative trajectory change) is arguably more likely than extinction following the creation of an extremely powerful agent with misaligned values (a level 2 event). We plan to write more about this in the future.
- Perhaps climate change could cause extinction for unknown reasons, but the risk of extreme global disruption short of extinction looks much higher.
- Perhaps geoengineering could result in the extinction of humanity, but extreme global disruption short of extinction again seems much more likely.
General reasons to think a global disruption might affect the distant future
This section argues that civilization has had unusually rapid progress over the last few hundred years, that the mechanisms of this progress are poorly understood, that we have essentially no experience with level 1 events, and that there is a risk that civilization will not fully recover if a level 1 event occurs.
The world has had unusually positive civilizational progress over the last few hundred years
Humanity has seen unparalleled scientific, technological, and social progress over the last few hundred years. Humanity’s scientific and technological progress resulted in the Industrial Revolution, whose consequences for per capita income can be observed in the following chart (from Maddison 2001, pg 42):
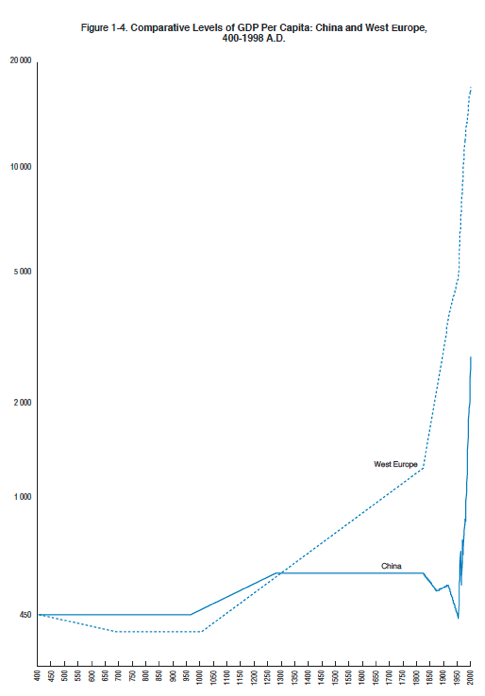
The groundwork for this revolution was laid by advances in previous centuries, so a “scientific and technological progress” chart wouldn’t look exactly like this “income per person” chart, but I’d guess it would look qualitatively similar (with the upward trajectory beginning somewhat sooner).
In terms of social progress, the last few centuries have seen the following, all of which I see as positive progress in terms of utilitarian-type values:
- The flowering of democracy
- The rise of tolerance for religious, ideological, and philosophical diversity
- The abolition of slavery
- The civil rights movement
- The rise of women’s equality and feminism
- The lowest levels of per capita violence in human history
(Note that many of these are discussed in The Better Angels of Our Nature, which Holden read, sought out criticism of, and wrote about here.)
I am aware of no other period in human history with comparable progress along these dimensions. I believe there is still significant room for improvement along many of these and other dimensions, which is one reason I see it as very important that this kind of progress continues.
There is little consensus about the mechanisms underlying civilizational progress
There is a large literature studying the causes of the Industrial Revolution and the “Great Divergence”—i.e. the process by which some countries leaped ahead of others (some of which later caught up, and some of which may catch up in the future) in terms of wealth and technological capacity. Explanations of this phenomenon have appealed to a variety of factors, as can be seen from this overview of recent work in economic history on this topic. My understanding is that there is no consensus about which of these factors played an essential role, or even that all potentially essential factors have been identified.
Most of the relevant literature I’ve found has primarily focused on the question, “Why did the Industrial Revolution happen in Europe and not in Asia?” and has little discussion of the question, “Why was there an Industrial Revolution at all, rather than not?” I spoke with some historians, economists, and economic historians to get a sense of what is known about the second question. David Christian, a historian in the field of “big history,” argued that (my non-verbatim summary):
[M]any aspects of the Industrial Revolution were not inevitable, but some extremely general aspects of industrialization (such as humans eventually gaining the ability to use fossil fuels) were essentially inevitable once there was a species capable of transferring substantial amounts of knowledge between people and across generations.
He also pointed to the fact that:
There were four “world zones” in history that didn’t interact with each other very much: Afro-Eurasia, the Americas, Australasia, and the Pacific. In Professor Christian’s view, these world zones developed at different rates along similar trajectories (though he emphasized that other historians might dispute this claim).
However, Professor Christian also cautioned that his view about the inevitability of technological progress was not generally shared by historians, who are often suspicious of claims of historical inevitability.
Other economic historians I spoke with argued against the inevitability of the degree of technological progress we’ve seen. For example, Joel Mokyr argued that (my non-verbatim summary):
A necessary ingredient to the Industrial Revolution in Europe was the development of a certain kind of scientific culture. This culture was unusual in terms of (i) its emphasis on experimentation and willingness to question conventional wisdom and authority, (ii) its ambition (illustrated in the thought of Francis Bacon) to find lawlike explanations for natural events, and (iii) its desire to use scientific discoveries to make useful technological advances.
If not for this unique cultural transformation in Europe, he argues, other countries would never have developed advanced technologies like digital computers, antibiotics, and nuclear reactors.
Though I have not studied the issue deeply, I would guess that there is even less consensus on the inevitability of the social progress described above. It seems that it would be extremely challenging to come to a confident view about the conditions leading to this progress. In the absence of such confidence, it seems possible that a catastrophe of unprecedented severity would disrupt the mechanisms underlying the unique civilizational progress of the last few centuries.
There is essentially no precedent for level 1 catastrophes
Some of the most disruptive past events have carried very large death tolls as a fraction of the world’s population, or as a fraction of the population of some region, including:
- The Black Death—which is estimated to have killed 75-200 million people, or 30-60% of the population of Europe/17-45% of the world’s population, from 1346-1350
- The 1918 flu pandemic—which is estimated to have killed 50-100 million people, or 3-5% of the world’s population
- World War I—which is estimated to have killed 15-65 million people, or 1-4% of the world’s population
- World War II—which is estimated to have killed 40-85 million people, or 2-4% of the world’s population
For the most part, these events don’t seem to have placed civilizational progress in jeopardy. However, it could be argued that World War II might have had a less favorable ultimate outcome, with potentially significant consequences for long-term trends in social progress. In addition there are very few past cases of events this extreme, and some potential level 1 events could be even more extreme. Moreover, the Black Death—by far the largest catastrophe on the list relative to population size—took place before the especially rapid progress began, so was less eligible to disrupt it. The remaining events on this list seem to have killed under 5% of the world’s population. Thus, past experience can provide little grounds for confidence that the positive trends discussed above would continue in the face of a level 1 event, especially one of unprecedented severity.
In this way, our situation seems analogous to the situation of someone who is caring for a sapling, has very limited experience with saplings, has no mechanistic understanding of how saplings work, and wants to ensure that nothing stops the sapling from becoming a great redwood. It would be hard for them to be confident that the sapling’s eventual long-term growth would be unaffected by unprecedented shocks—such as cutting off 40% of its branches or letting it go without water for 20% longer than it ever had before—even taken as given that such shocks wouldn’t directly/immediately result in its death. For similar reasons, it seems hard to be confident that humanity’s eventual long-term progress would be unaffected by a catastrophe that resulted in hundreds of millions of deaths.
If I believed that sustained scientific, technical and social progress were inevitable features of the world, I would see a weaker connection between the occurrence of level 1 events and the long-term fate of humanity. If I were confident—for example—that a level 1 event would simply “set back the clock” and let civilization replay itself essentially unchanged—then I might believe it would take something like a level 2 event to change civilization’s long-term trajectory. But the limited room for understanding the causes of progress over the last few centuries and the world’s essentially negligible experience with extreme events do not offer grounds for confidence in that perspective.
Specific mechanisms by which a catastrophe could affect the distant future
In addition to the above general and non-specific reasons to expect that a level 1 event could devastate the future, I can also think of specific mechanisms by which civilizational progress could be disrupted, and mechanisms by which such disruption could be bad for the fate of humanity.
Disruption of sustained scientific and technological progress
Suppose that sustained scientific and technological progress requires all of:
- A large enough number of scientists with deep tacit knowledge of methods of innovative science
- A large enough number of talented students willing and able to absorb that tacit knowledge from their teachers
- Innovators with tacit knowledge and scientific understanding needed to develop new technologies that harness the potential unleashed by scientists
- Institutions that provide support for science and allow for technological innovation
Imagine a level 1 event that disproportionately affected people in areas that are strong in innovative science (of which we believe there are a fairly contained number). Possible consequences of such an event might include a decades-long stall in scientific progress or even an end to scientific culture or institutions and a return to rates of scientific progress comparable to what we see in areas with weaker scientific institutions today or saw in pre-industrial civilization. Speaking very speculatively, this could lead to various failures to realize humanity’s long-term potential, including:
- Risky stall: Perhaps—during a lengthy stall in scientific progress—some other catastrophe would make humanity go extinct. If the rate of progress were slow enough, even a low background rate of natural extinction events could become important (this background rate would likely fall if civilization developed the capacity for space colonization or created advanced artificial intelligence). But such a catastrophe could also rely on advanced technology because there is a distinction between creating new innovations and using and spreading existing innovations, and the background risk for those events may be much greater. This risk might be especially salient if the initial catastrophe occurred during a period where humanity had significantly more powerful weapons technology, such as the next generation of biological weapons. Alternatively, during this lengthy window of weakness, an authoritarian regime could take root; perhaps advanced technology would make its power permanent, and lead to a flawed realization of the future.
- Resource depletion and environmental degradation: A lengthy stall in scientific progress may allow enough time to pass that other negative trends—such as the depletion of essential resources or accumulation of climate change over hundreds of years in a world without technological solutions to the problem—could result in a permanent decrease in humanity’s future potential. For example, perhaps civilization could use up essentially all available fossil fuels before finding suitable replacements, potentially making it much more challenging to retrace steps through technological history.
- Permanent stagnation: If scientific culture or institutions never returned, perhaps civilization would never develop some important technologies, such as those needed for space colonization.
Disruption of sustained social progress
As with scientific progress, social progress (in terms of the utilitarian-type value, as discussed above) seems to have been disproportionately concentrated in recent centuries, and its mechanisms remain poorly understood.
A global catastrophe could stall—or even reverse—social progress from a utilitarian-type perspective. Once again, especially if the catastrophe disproportionately struck particularly important areas, there could be a stoppage/stall in social progress, or a great decrease in the comparative power of open societies in comparison with authoritarian regimes. This could result in a number of long-term failure scenarios for civilization. For example:
- Negative cultural trajectory: It seems possible that just as some societies reinforce openness, toleration, and equality, other societies might reinforce alternative sets of values. (For example, it is possible – as implied in The Better Angels of Our Nature for example – that the kind of social progress I’m highlighting is connected to scientific culture or institutions, and could be comparably fragile.) Especially if culture continues to become increasingly global, it may become easier for one kind of culture to dominate the world. A culture opposed to open society values, or otherwise problematic for utilitarian-type values, could permanently take root. Or, given certain starting points, cultural development might not inevitably follow an upward path, but instead explore a (from a utilitarian-type perspective) suboptimal region of the space of possible cultures. Even if civilization reaches technological maturity and colonizes the stars, this kind of failure could limit humanity’s long-term potential.
- Authoritarian regime inhibits scientific progress: A catastrophe could push the world in the direction of control by an authoritarian regime. An authoritarian regime with geopolitical clout analogous to what the U.S. has today could unleash many of the risks discussed above.
- Reversion toward inter-state violence: A sufficiently extreme catastrophe could threaten the conditions that have to led the historical decline of inter-state violence. During the Cold War, the USSR employed tens of thousands of researchers in a secret biological weapons program. In a world where the trend toward peace were disrupted but technological progress continued, the destructive potential of a such a research program could become much greater. The result could be a later Level 2 event, which might happen more easily if humanity is already in a weakened condition.
- Irrevocable technological mistakes: Irrevocable technological mistakes might be made by people who lack the necessary wisdom and foresight. This possibility seems more disturbing in a world with fewer highly capable and human-welfare-oriented people and/or less favorable geopolitical conditions, relative to what exists today (today seems favorable on these dimensions by historical standards). For example, it seems to me that the risk of creating a superintelligent artificial intelligence with misaligned values would be significantly heightened if—rather than being created by highly capable scientists in open societies—advanced artificial intelligence were developed by less capable and thoughtful scientists in a violence-prone world under the guidance of an authoritarian regime. Likewise, if humanity pursued advanced forms of genetic enhancement or geoengineering, I would like to see those fraught choices made under the most favorable possible circumstances, and today’s circumstances seem quite favorable relative to historical norms.
Potential offsetting factors
So far my discussion has focused on how a global catastrophe could negatively affect the fate of humanity. Are there any potential mechanisms by which a global catastrophe could make our future seem brighter from the perspective assumed in this post (prioritizing maximal long-term potential, preferably including space colonization)?
In conversations, I have heard the following arguments for why this is possible:
- Warning shots: If civilization survives the level 1 event, perhaps the event will serve as a “warning shot,” and cause society to make more appropriate preparations for level 2 events.
- Ills of modernity: Perhaps civilizational “progress” is actually negative—for example because of the effects it has on the environment, the way it promotes inequality, the way it has led humans to treat animals, or the way it has stamped out traditional cultures and values. If it were disrupted, perhaps that would be a good thing.
- More preparation for critical technological junctures: Perhaps a catastrophe would set back industrial capacity and development, but would not set back scientific and social progress by as great a factor. This might mean that when humanity reaches critical junctures of technological development—such as advanced artificial intelligence, powerful genetic enhancement, or atomically precise manufacturing—civilization will be more mature, and more ready to handle the subsequent challenges.
I want to acknowledge these possible objections to our line of reasoning, but do not plan to discuss them deeply. My considered judgment—which would be challenging to formally justify and I acknowledge I have not fully explained here—is that these factors do not outweigh the factors pushing in the opposite direction.
Some reasons for this:
- Overspecificity of reactions to warning shots: It may be true that, e.g., the 1918 flu pandemic served as a warning shot for more devastating pandemics that happened in the future. For example, it frequently gets invoked in support of arguments for enhancing biosecurity. But it seems significantly less true that the 1918 flu pandemic served as a warning shot for risks from nuclear weapons, and it is not clear that the situation would change if one were talking about a pandemic more severe than the 1918 flu pandemic. If a level 1 event carries many of the risks discussed above, it would seem to be an extremely high price to pay for increasing society’s willingness to prepare for a level 2 event of the same type.
- Better solutions to the ills of modernity: Though I would agree that civilizational progress has brought problems as well as improvements, my opinion is that it is firmly on the positive side of the ledger on net. Moreover, correcting many of the problems of civilization seems possible at costs much lower than allowing a level 1 event to occur.
- Less preparation for critical technological junctures: I believe it is very challenging to prepare for critical technological junctures like creating advanced artificial intelligence decades prior to the arrival of the technology, both because it is hard to know what kind of work will be needed and hard to know what kind of work will not be done. I would guess that much of the preparation will become much easier as the technologies draw closer in time. By contrast, the characteristics of the people and institutions responsible for dealing with these challenges seem robustly important. It therefore seems to me that there is more room for the factors discussed under “irrevocable technological mistakes” to lead to heightened risk than for pushing back technological progress to lead to decreased risk.
Conclusion and strategic implications
I believe that seeking to prepare for global catastrophes that could result in deaths amounting to a substantial fraction of the world’s population may be important for humanity’s future because:
- Events with hundreds of millions of deaths are much more probable than direct extinction events.
- These events could potentially derail civilizational progress (either temporarily or permanently) and thereby prevent humanity from realizing its full potential. Since these less extreme catastrophes are also much more probable than direct extinction events, preparing for them seems in the same rough ballpark of importance as preparing for direct extinction events.
- The mechanisms of civilization’s progress are poorly understood, and there are essentially no precedent shocks of the size we are seeking to prevent. I see no way to rule out the possibility that an event with hundreds of millions of deaths would affect the ultimate fate of humanity.
As such, I believe that a “dual focus” approach to global catastrophic risk mitigation is appropriate, even when making the operating assumptions of this post (a focus on long-term potential of humanity from a utilitarian-type perspective).
Advanced artificial intelligence seems like the most plausible area where an outright extinction event (e.g. due to an extremely powerful agent with misaligned values) may be comparably likely to a less extreme global catastrophe (e.g. due to the use of extremely powerful artificial intelligence to disrupt geopolitics). We plan to discuss this issue further in the future.
Acknowledgements
Thanks to the following people for reviewing a draft of this post and providing thoughtful feedback (this of course does not mean they agree with the post or are responsible for its content): Alexander Berger, Nick Bostrom, Paul Christiano, Owen Cotton-Barratt, Daniel Dewey, Eric Drexler, Holden Karnofsky, Howie Lempel, Luke Muehlhauser, Toby Ord, Anders Sandberg, Carl Shulman, and Helen Toner.